Schlagwort Ollama
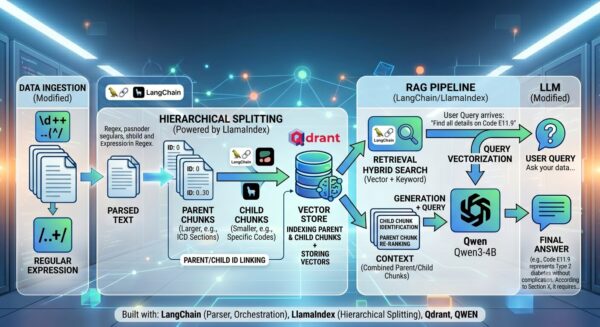
Du betreibst RAG mit einem lokalen LLM – und die Antworten sind ungenau, fragmentiert oder völlig daneben. Du verdoppelst den Kontextfenster, steigst auf ein größeres Modell um, und plötzllich brauchst du eine GPU mit >24 GB VRAM oer Cloudmodelle, nur