Du betreibst RAG mit einem lokalen LLM – und die Antworten sind ungenau, fragmentiert oder völlig daneben. Du verdoppelst den Kontextfenster, steigst auf ein größeres Modell um, und plötzllich brauchst du eine GPU mit >24 GB VRAM oer Cloudmodelle, nur um eine einfache Frage zu beantworten.
Das Problem ist fast nie das Modell allein. Es ist das Retrieval.
Wenn die rekonstruierten Chunks zu klein sind, fehlt dem Modell der Kontext. Sind sie zu groß, verliert der Embedding-basierte Retriever die Präzision.
Du stehst vor dem klassischen Chunkingdilemma – und genau hier kommt Parent/Child-Chunking ins Spiel.
Disclaimer
Dieses Setup zeigt in erster Linie wie, mit gezielten Methoden, das maximalste aus einem kleinen Setup geholt werden kann.
Regex in Verbindung mit der richtigen Strategie ist, nach meiner Erfahrung, immer stärker als bloßes, hartes, chunken an bestimmten Grenzen (MardownSplitter, RecursiveCharacterSplitter usw).
Zudem können so die wichtigen Metadaten in der Datenbank besser und gezielter gefüllt werden.
Der Use-Case: ICD-10-GM-Code-Suche
Ein realistisches Szenario: Du willst eine Chat-Frage wie „Welche ICD-Codes für Diabetes mellitus gibt es?“ gegen das ICD-10-GM 2026-Referenzdokument des BfArM beantworten. Dutzende von Codes, Unter-Codes, Inklusionen und Exklusionen – auf über 850 Seiten.
Ein naives fixed-size-Chunking zerschneidet die Code-Blöcke willkürlich. Der Retriever findet Fragmente ohne den übergeordneten Code-Kontext. Das kleine 4-Parameter-Modell hat nichts Sinnvolles zum Zusammenfassen.
Parent/Child-Chunking löst dieses Problem elegant: Kleine, präzise Chunks für das Retrieval. Große, kontextreiche Blöcke für die Generierung.
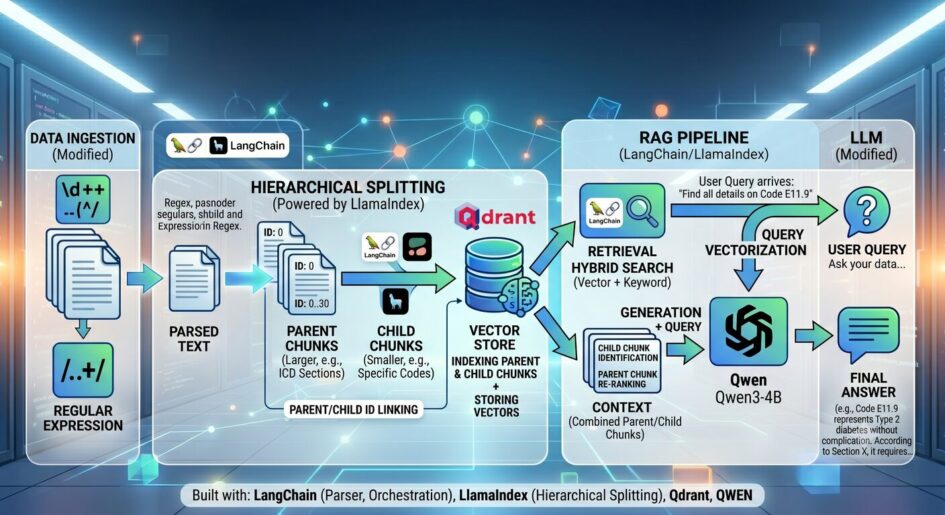
Wie Parent/Child-Chunking funktioniert
Das Konzept ist simpel:
- Parent-Nodes sind große Textblöcke (hier: ganze PDF-Seiten). Sie liefern den vollständigen Kontext für die Antwortgenerierung.
- Child-Nodes sind kleine, semantisch dichte Abschnitte (hier: einzelne ICD-Code-Blöcke). Sie ermöglichen präzises Retrieval.
Der Retriever sucht nur in den Child-Nodes. Findet er einen Treffer, wird automatisch der zugehörige Parent-Node nachgeladen. Das LLM bekommt also immer den vollen Kontext – aber das Retrieval bleibt präzise.
Schritt 1: Regex-basiertes Extrahieren der ICD-Code-Blöcke
Zuerst extrahieren wir die Child-Nodes direkt aus den PDF-Seiten. Der Trick ist ein Regex-Muster, welches ICD-Codes erkennt und die Textabschnitte zwischen ihnen splittet.
import re
from pypdf import PdfReader
pdf = PdfReader("icd10gm2026syst_referenz_20250912.pdf")
chunks = []
for page in pdf.pages:
pattern = r'([A-Z][0-9][0-9](?:\.[0-9A-Z]+)?)'
extract = page.extract_text()
codes = re.findall(pattern, extract)
for i, code in enumerate(codes):
start = extract.find(code)
end = extract.find(codes[i+1], start) if i+1 < len(codes) else len(extract)
section = extract[start:end].strip()
chunks.append({
"code": code,
"text": section,
"page_number": pdf.pages.index(page) + 1
})Der Regex ([A-Z][0-9][0-9](?:\.[0-9A-Z]+)?) erkennt ICD-Codes wie E11.2, D65.0 oder Z13.1. Jeder Treffer wird zum Startpunkt eines Child-Chunk – der Text reicht bis zum nächsten Code-Beginn.
Ein Beispiel-Chunk sieht so aus:
# chunks[6]
{
'code': 'D65.0',
'text': 'D65.0 Erworbene Afibrinogenämie wurde umbenannt in: '
'D65.0- Afibrinogenämie und Hypofibrinogenämie, erworben...',
'page_number': 5
} Schritt 2: Parent- und Child-Nodes erstellen
from llama_index.core.schema import TextNode
# Parent Docs – ganze Seiten
parent_docs = []
for i, page in enumerate(pdf.pages):
parent_docs.append(
TextNode(
text=page.extract_text(),
metadata={
'Author': 'BfArM',
'Title': 'ICD-10-GM Version 2026 Systematisches Verzeichnis',
'Page': pdf.pages.index(page) + 1
}
)
)
# Child Docs – Code-basierte Chunks
child_docs = []
for chunk in chunks:
child_docs.append(
TextNode(
text=chunk['text'],
metadata={
'ICD_Code': chunk['code'],
'Page': chunk['page_number'],
'Title': 'ICD-10-GM Version 2026 Systematisches Verzeichnis'
}
)
)
Schritt 3: Beziehungen zwischen Parent und Child definieren
Child-Nodes werden mit ihren Eltern über NodeRelationship verknüpft.
from llama_index.core.schema import NodeRelationship, RelatedNodeInfo
for parent in parent_docs:
for child in child_docs:
if child.metadata['Page'] == parent.metadata['Page']:
child.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=parent.node_id
)
child.metadata['parent_id'] = parent.node_id
child.metadata['node_type'] = "child"
parent.relationships.setdefault(NodeRelationship.CHILD, [])
parent.relationships[NodeRelationship.CHILD].append(
RelatedNodeInfo(node_id=child.node_id)
)
parent.metadata['node_type'] = "parent"Die Matching-Logik ist hier einfach: Child und Parent teilen sich dieselbe Seitenzahl. In komplexeren Use-Cases könntest du auch hierarchische Code-Strukturen abbilden.
Schritt 4: Qdrant mit Hybrid-Indexing
Das Embedding-Modell ist BAAI/bge-m3 – ein großes, leistungsfähiges Multi-Vector-Modell, das sowohl dense als auch sparse Vektoren produziert. Perfekt für Qdrants Hybrid-Suche.
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import qdrant_client
from qdrant_client import models
embeddings = HuggingFaceEmbedding(model_name="BAAI/bge-m3", device="cuda")
client = qdrant_client.QdrantClient("http://localhost:6333", api_key="loc-123")
if not client.collection_exists("icd_ops"):
client.create_collection(
collection_name="icd_ops",
vectors_config=models.VectorParams(size=1024, distance=models.Distance.COSINE),
sparse_vectors_config={
"text-sparse": models.SparseVectorParams(
index=models.SparseIndexParams(on_disk=False)
)
}
)
# Payload-Indizes für schnelles Filtern
client.create_payload_index(
collection_name="icd_ops",
field_name="metadata.node_type",
field_schema=models.PayloadSchemaType.KEYWORD,
)
client.create_payload_index(
collection_name="icd_ops",
field_name="metadata.parent_id",
field_schema=models.PayloadSchemaType.KEYWORD,
)Zwei Details sind hier wichtig:
- Sparse Vektoren in Qdrant ermöglichen BM25-basierte Keyword-Suche neben der semantischen Vektor-Suche. Das ist entscheidend für exakte ICD-Code-Treffer.
- Payload-Indizes auf
node_typeundparent_idermöglichen schnelles Filtern nach Parent/Child-Typ in Millisekunden.
Schritt 5: Der RecursiveRetriever
Der RecursiveRetriever von LlamaIndex ist der Schlüsselmechanismus. Er sucht zuerst in den Child-Nodes und expandiert dann automatisch auf die Parent-Nodes:
from llama_index.core.retrievers import RecursiveRetriever
base_retriever = index.as_retriever(similarity_top_k=20)
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": base_retriever},
node_dict={node.node_id: node for node in all_nodes},
verbose=True
)
result = recursive_retriever.retrieve("Welche ICD Codes für Diabetes mellitus gibt es?")
Der Retriever findet relevante Child-Chunks (z. B. E11.2, E13.-, R73.08) und lädt dann automatisch die gesamten PDF-Seiten als Kontext nach. Das Ergebnis ist ein präzises Retrieval + voller Kontext.
Schritt 6: Antwortgenerierung mit einem kleinen Modell
Die Antwort wird mit einem vergleichsweise kleinen Qwen3:4B Modell über Ollama bereitgestellt – lokal, kostenlos, schnell.
from langchain_ollama import ChatOllama
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
model = ChatOllama(model="qwen3:4b", temperature=0.1)
context = "\n\n".join([doc.text for doc in result])
prompt = PromptTemplate.from_template(
"Basierend auf dem folgenden Kontext beantworte die Frage präzise und ausführlich:\n\n"
"Lasse keine Informationen weg und erfinde keine Antworten.\n\n"
"Liste in Bulletpoints auf.\n"
"Kontext:\n{context}\n\n"
"Frage: {question}\n\n"
"Antwort:\n\n"
)
qa = prompt | model | StrOutputParser()
answer = qa.invoke({'context': context, 'question': "Welche ICD Codes für Diabetes mellitus gibt es?"})
Und das Ergebnis? Das 4B-Modell liefert eine strukturierte, präzise Antwort mit korrekten ICD-Codes:
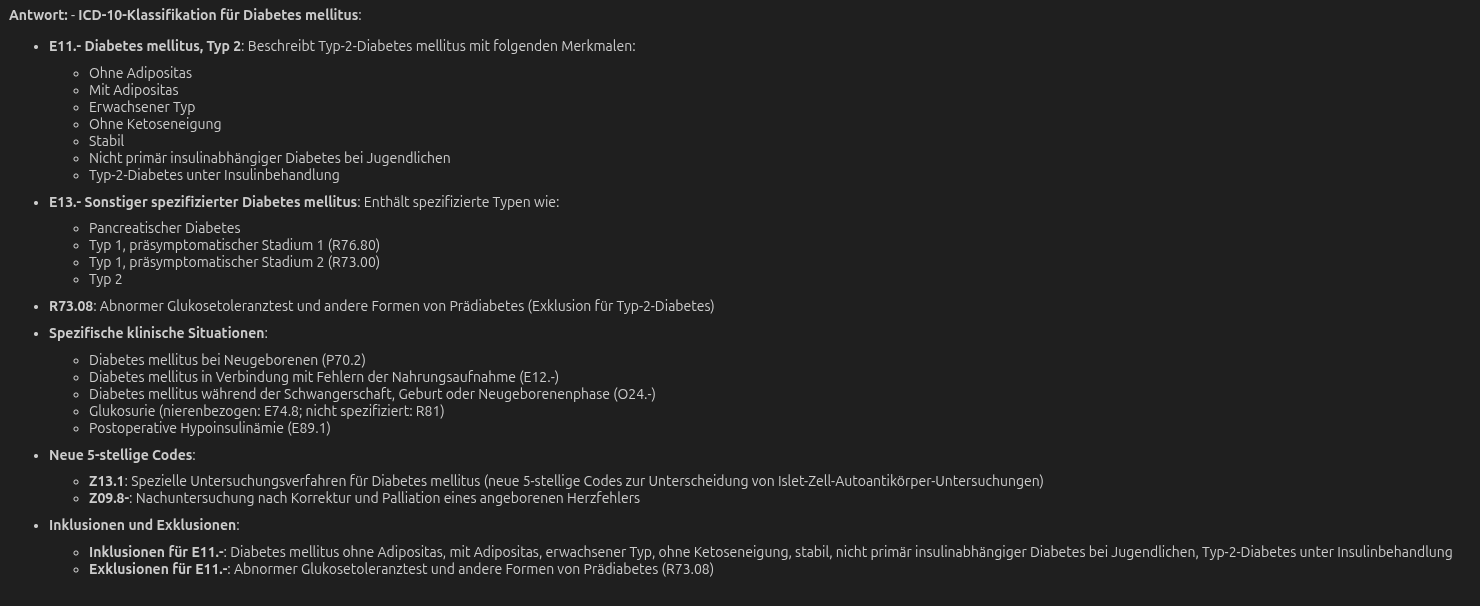
Das ist keine Halluzination. Das sind die tatsächlichen Codes aus dem ICD-10-GM-Referenzdokument – korrekt extrahiert, korrekt zugeordnet.
Warum dieser Stack funktioniert
Drei Architekturentscheidungen tragen die Last:
- Embedding-Güte vor Modell-Größe: BGE-M3 ist groß (multi-lingual, dense + sparse), aber das ist ein einmaliger Kostenpunkt. Das LLM muss klein bleiben können.
- Retrieval-Präzision durch kleine Chunks: Die ICD-Code-Blöcke sind klein genug, dass der Retriever den semantisch relevantesten Chunk findet.
- Kontext-Erhaltung durch Parent-Expansion: Der RecursiveRetriever liefert die volle Seite – das kleine Modell braucht nicht zu raten, was zwischen den Chunk-Grenzen verloren ging.
Key Takeaways
- Parent/Child-Chunking entkoppelt Retrieval-Präzision von Generierungs-Kontext. Kleine Chunks suchen, große Chunks liefern.
- Regex-basiertes Splitting ist oft besser als fixed-size-Chunking, wenn deine Daten eine inhärente Struktur haben (ICD-Codes, Kapitel, Abschnitte).
- Hybrid-Suche (dense + sparse) in Qdrant kombiniert semantisches Verständnis mit exakter Keyword-Matching. Unverzichtbar bei fachlichen Dokumenten.
- Ein großes Embedding-Modell kompensiert ein kleines LLM. Die Investition in gute Embeddings zahlt sich aus.
- Der RecursiveRetriever von LlamaIndex automatisiert das Parent-Nachladen – keine manuelle Join-Logik nötig.
- 4 Parameter reichen aus, wenn das Retrieval stimmt. Qwen3:4B lokal via Ollama ist ein praktikabler Stack für produktive RAG-Anwendungen.
Der Takeaway ist klar: Wenn dein RAG mit kleinen Modellen nicht funktioniert, ist das Problem selten das Modell. Es ist das Retrieval. Und Regex in Verbindung mit Parent/Child-Chunking sind effektive Hebel, die du drehen kannst.
Schreibe einen Kommentar