Schlagwort Qdrant
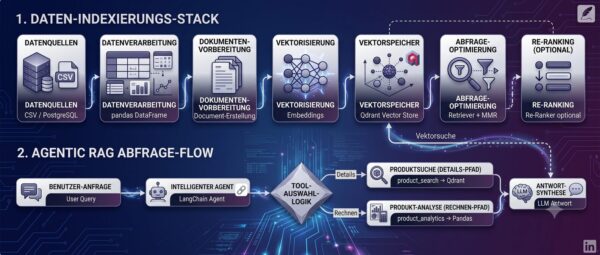
RAG auf CSV- und SQL-Daten: Warum Embeddings allein nicht reichen „Wie hoch ist unser Gesamtgewinn bei Möbeln?“ – und das RAG-System antwortet falsch. Nicht weil das LLM dumm ist. Nicht weil die Embeddings schlecht sind. Der Grund ist tiefer: Embeddings
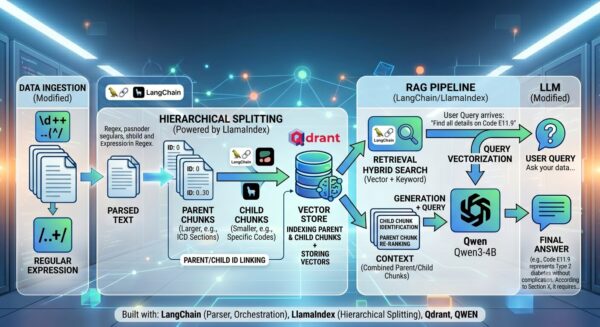
Du betreibst RAG mit einem lokalen LLM – und die Antworten sind ungenau, fragmentiert oder völlig daneben. Du verdoppelst den Kontextfenster, steigst auf ein größeres Modell um, und plötzllich brauchst du eine GPU mit >24 GB VRAM oer Cloudmodelle, nur