RAG auf CSV- und SQL-Daten: Warum Embeddings allein nicht reichen
„Wie hoch ist unser Gesamtgewinn bei Möbeln?“ – und das RAG-System antwortet falsch.
Nicht weil das LLM dumm ist. Nicht weil die Embeddings schlecht sind. Der Grund ist tiefer: Embeddings können nicht rechnen.
Wenn du RAG auf strukturierte Daten anwendest – CSV-Dateien, SQL-Tabellen, Excel-Sheets – stößt du an eine Grenze, die in fast jedem Tutorial verschwiegen wird. Die Pipeline funktioniert für textbasierte Fragen perfekt. Aber sobald Zahlen, Summen, Durchschnitte oder Aggregationen ins Spiel kommen, liefert der Vektor-Retriever nur noch Rauschen.
In diesem Artikel zeige ich, warum das passiert – und wie du mit einem Hybrid-Ansatz aus semantischer Vektorsuche und Pandas-basierten Berechnungen einen Agent baust, der beides kann.
Das Problem: Embeddings verstehen Semantik, nicht Mathematik
Ein Embedding-Modell wie all-MiniLM-L6-v2 wandelt Text in Vektoren um, die semantische Ähnlichkeit abbilden. Fragst du nach „Holztisch mit natürlicher Farbe“, findest du exakt das richtige Produkt. Das ist brilliant.
Aber stell dir vor, du fragst: „Welches Produkt hat den höchsten Gewinn pro Kategorie?“ oder „Summiere den Umsatz aller aktiven Bestellungen“. Die Embeddings dieser Fragen ähneln numerisch vielleicht den Embeddings einzelner Produktdokumente – aber sie enthalten keine Information über Summen, Durchschnitte oder Vergleiche.
Das ist kein Bug. Es ist ein fundamentales Limit der Architektur.
Embeddings lösen das Retrieval-Problem für unstrukturierte Textdaten. Nicht für strukturierte Tabellendaten.
Der Hybrid-Ansatz: Zwei Tools, zwei Welten
Die Lösung ist nicht „bessere Embeddings“. Die Lösung ist: Trenne semantische Suche von numerischer Analyse.
In meinem Projekt habe ich einen LangChain-Agent mit genau zwei Tools gebaut:
Tool 1: product_search – Semantische Suche in Qdrant
Dieses Tool ruft den Vektor-Retriever auf und liefert Detailinformationen zu einzelnen Produkten: Namen, Beschreibungen, Lieferanten, Adressen.
@tool
def product_search(query: str):
"""
Nutze dieses Tool um detaillierte Informationen über einzelne Produkte zu erhalten.
"""
return retriever.invoke(query)
Es deckt Fragen wie diese ab:
– „Zeig mir alle Produkte aus Holz“
– „Welche Artikel ähneln einem Schreibtisch?“
– „Gib mir die Kontaktinformationen des Lieferanten XY“
Tool 2: product_analytics – Exakte Berechnungen mit Pandas
Dieses Tool führt Pandas-Code auf dem DataFrame aus. Der Agent generiert den Code selbst – und das Tool führt ihn kontrolliert aus.
from pydantic import BaseModel, Field
class PandasQuery(BaseModel):
code: str = Field(
description="Der exakte Python/Pandas Code, der auf dem DataFrame 'df' ausgeführt werden soll."
)
@tool(args_schema=PandasQuery)
def product_analytics(code: str):
"""
Nutze dieses Tool für Berechnungen auf den Unternehmensdaten.
Verfügbare Spalten: Produktname, Produktkategorie, Umsatz, Gewinn, etc.
"""
try:
if "import" in code or "os." in code:
return "Fehler: Nur Pandas-Operationen erlaubt."
return str(eval(code, {"df": data, "pd": pd}))
except Exception as e:
return f"Fehler im Code: {str(e)}. Bitte überprüfe die Spaltennamen."
Dieses Tool löst:
– „Wie viel Gewinn machen wir mit Möbeln?“
– „Durchschnittlicher Preis pro Kategorie“
– „Top 5 Produkte nach Umsatz“
Von strukturiert zu unstrukturiert: Die Transformation
Damit die Vektordatenbank überhaupt arbeiten kann, müssen CSV-Zeilen in Textdokumente umgewandelt werden. Jede Zeile des DataFrames wird zu einem LangChain Document:
import hashlib
from datetime import datetime, timezone
def generate_id(content: str) -> str:
"""Generiert eine stabile ID basierend auf dem Produktcode."""
return hashlib.md5(content.encode()).hexdigest()
sync_timestamp = datetime.now(timezone.utc).isoformat()
documents = []
for idx, row in data.iterrows():
content_parts = [f"{col}: {row[col]}" for col in data.columns]
full_content = "\n".join(content_parts)
metadata = {
"kategorie": row['produktkategorie'],
"produktname": row['produktname'],
"produktcode": row['produktcode'],
"status": row['bestellstatus'],
"Last_Sync": sync_timestamp
}
documents.append(Document(page_content=full_content, metadata=metadata))
Das Ergebnis sieht so aus:
produktname: Bücherregal
produktkategorie: Möbel
produktbeschreibung: Hochwertiges Bücherregal
produktgewicht_kg: 22.0
produktfarbe: natürlich
...
Der Text enthält nun alle 40 Spalten als lesbares Dokument – perfekt für semantische Suche. Gleichzeitig bleiben strukturierte Filter über die metadata möglich.
Stabile IDs durch Hashing
Qdrant braucht eindeutige IDs für Updates. Ein MD5-Hash des Produktcodes garantiert: Gleicher Produktcode = gleiche ID. Keine Duplikate, saubere Updates.
ids.append(generate_id(str(row['produktcode'])))
Sync-Mechanismus: Warum deine Vektordatenbank sonst wertlos wird
CSV- und SQL-Daten ändern sich. Produkte werden gelöscht, Preise angepasst, neue Artikel hinzugefügt. Wenn die Vektordatenbank nicht mitkommt, antwortet dein RAG-System auf Basis veralteter Daten – und das ist schlimmer als keine Antwort.
Die Lösung: Ein Last_Sync-Timestamp in der Metadata jedes Dokuments.
- Beim Laden erhält jedes Dokument den aktuellen UTC-Timestamp.
- Vor dem Insert werden alle Dokumente mit einem veralteten Timestamp gelöscht.
client.delete(
collection_name=collection_name,
points_selector=models.FilterSelector(
filter=models.Filter(
must_not=[
models.FieldCondition(
key="metadata.Last_Sync",
match=models.MatchValue(value=sync_timestamp),
)
]
)
)
)
Das Ergebnis: Deine Vektordatenbank bleibt automatisch synchron mit der Quelldatei – ohne manuelle Pflege.
MMR-Retrieval: Warum 20 Tische nicht 20 Tische sein müssen
Ein häufiges Problem bei Produktkatalogen: Reine Ähnlichkeitssuche liefert redundante Ergebnisse. Fragst du nach „Tisch“, bekommst du 20 Varianten desselben Produkts zurück.
Maximum Marginal Relevance (MMR) löst das, indem es Relevanz und Diversität balanciert:
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={
'k': 20,
'fetch_k': 50,
'lambda_mult': 0.5,
}
)
k=20: Gibt 20 Ergebnisse zurückfetch_k=50: Holt zuerst 50 Kandidatenlambda_mult=0.5: 50/50-Mischung aus Relevanz und Diversität
Das Ergebnis ist eine vielfältigere Produktliste, die unterschiedliche Kategorien und Preisbereiche abdeckt.
Re-Ranking: Qualität vor allem
Optional, aber impactful: Ein Cross-Encoder Re-Ranker sortiert die initiale Ergebnisliste neu und filtert auf die Top 5.
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_classic.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
model = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
compressor = CrossEncoderReranker(model=model, top_n=5)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
Der Re-Ranker versteht den Kontext der User-Frage besser als der Embedding-Retriever allein – und liefert konsistent relevantere Ergebnisse.
Der System-Prompt: Das fehlende Puzzleteil
Der kritischste Erfolgsfaktor dieses ganzen Setups ist nicht die Vektordatenbank. Nicht das Embedding-Modell. Es ist der System-Prompt.
Ohne explizite Anweisungen wählt das LLM das falsche Tool. Es versucht, Summenberechnungen über Embeddings zu lösen – und scheitert.
system_msg = f"""
Du bist ein Assistent für Unternehmensdaten.
Die Daten enthalten folgende Felder: {column_list}.
TRENNUNG DER TOOLS:
1. Nutze 'product_search', wenn du nach DETAILS zu einzelnen Produkten,
Lieferanten, Kunden oder spezifischen Werten wie E-Mails oder Adressen suchst.
2. Nutze 'product_analytics' (Pandas), wenn du RECHNEN musst:
Summen, Durchschnitte, Zählungen, oder wenn du Daten über alle Zeilen
hinweg vergleichen musst.
BEISPIEL WENN DU product_analytics EINSETZT:
User: 'Wie viele Kategorien gibt es?'
Thought: Ich muss die Anzahl der eindeutigen Werte in der Spalte 'Produktkategorie' zählen.
Action: product_analytics(code="df['Produktkategorie'].nunique()")
Observation: 5
Final Answer: Es gibt insgesamt 5 verschiedene Produktkategorien.
"""
Drei Prinzipien im Prompt:
- Explizite Spaltenliste – Das LLM muss wissen, welche Felder existieren.
- Klare Tool-Trennung – Wann welches Tool – ohne Grauzonen.
- Few-Shot-Beispiel – Thought-Action-Observation-Muster zeigt das korrekte Verhalten.
Security: Wenn dein LLM Code ausführt
eval() auf User-Input ist mächtig. Und gefährlich. Ein Nutzer könnte versuchen, das LLM zu schädlichem Code zu verleiten.
Der Schutz ist simpel, aber notwendig:
if "import" in code or "os." in code:
return "Fehler: Nur Pandas-Operationen erlaubt."
- Kein
import– keine neuen Module laden. - Kein
os.– keinen Dateisystem-Zugriff. - Nur lesende Pandas-Operationen auf dem DataFrame.
In Produktion würde ich das weiter ausbauen – etwa mit einem White-List-Ansatz oder Sandboxing. Aber als Minimum ist dieser Check unverzichtbar.
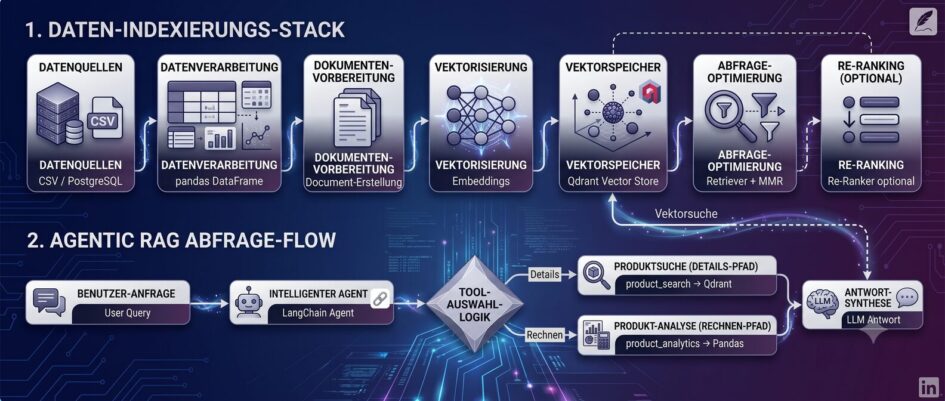
Der komplette Stack
| Komponente | Technologie | Zweck |
|---|---|---|
| Datenquelle | CSV / PostgreSQL | 40-Spalten Handelsdaten |
| Verarbeitung | pandas | DataFrame-Operationen |
| Embedding | all-MiniLM-L6-v2 | Lokales, kostenloses Modell |
| Vektordatenbank | Qdrant | Persistente semantische Suche |
| LLM | ministral-3:8b via Ollama | Tool-Orchestrierung |
| Framework | LangChain | Agents, Tools, RAG-Pipeline |
| Re-Ranker | BAAI/bge-reranker-base | Cross-Encoder Re-Ranking |
Beide Datenquellen – CSV und SQL – nutzen dieselbe Pipeline. Der einzige Unterschied ist der Daten-Ladepunkt:
# CSV
data = pd.read_csv('data_analysis/trading_data.csv', delimiter=";")
# SQL
data = pd.read_sql("trading_data", engine)
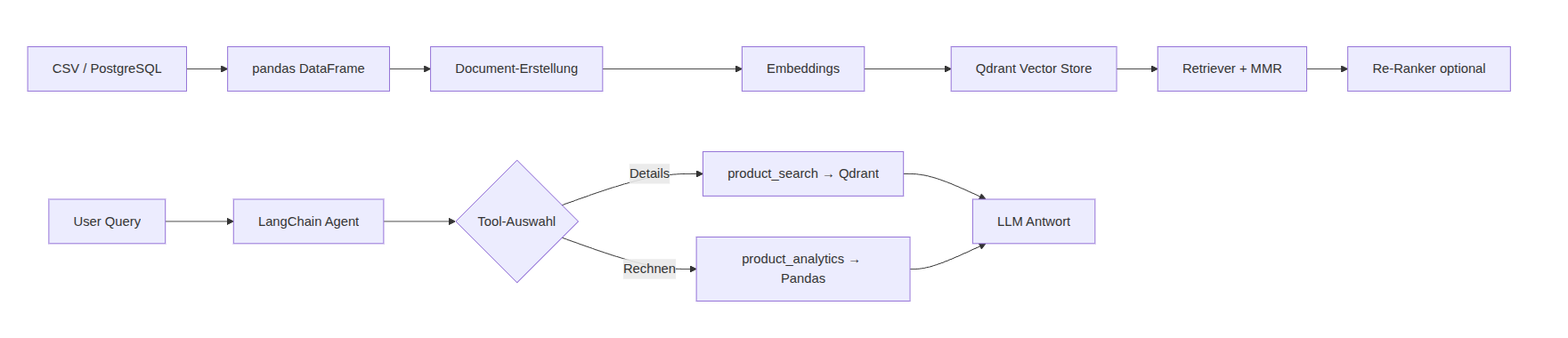
Der End-to-End-Flow
graph LR
A[CSV / PostgreSQL] --> B[pandas DataFrame]
B --> C[Document-Erstellung]
C --> D[Embeddings]
D --> E[Qdrant Vector Store]
E --> F[Retriever + MMR]
F --> G[Re-Ranker optional]
H[User Query] --> I[LangChain Agent]
I --> J{Tool-Auswahl}
J -->|Details| K[product_search → Qdrant]
J -->|Rechnen| L[product_analytics → Pandas]
K --> M[LLM Antwort]
L --> M
Ein konkreter Ablauf:
- Query: „Wieviel Gewinn machen wir mit unserem Schreibtisch?“
- Agent wählt
product_search– es geht um Details zu einem einzelnen Produkt. - Retriever liefert das passende Dokument aus Qdrant.
- LLM extrahiert den Gewinn: „40,00 EUR pro Verkauf.“
- Antwort: „Mit dem Schreibtisch machen wir einen Gewinn von 40,00 EUR pro Verkauf.“
Alles automatisch. Kein manueller Prompt-Engineering-Prozess. Der Agent entscheidet selbst.
Key Takeaways
- Embeddings sind keine Allzwecklösung. Sie lösen semantische Suche – nicht numerische Analyse.
- Hybrid-Ansatz ist die richtige Architektur. Trenne Vektorsuche von symbolischer Verarbeitung.
- Der System-Prompt ist der Hebel. Explizite Tool-Trennung und Few-Shot-Beispiele machen den Unterschied zwischen funktionierendem Agent und Raten.
- Sync-Mechanismen sind Pflicht, kein Bonus. Ohne sie wird die Vektordatenbank zum Datenfriedhof.
- Security zählt ab Minute 1. Code-Execution durch LLMs braucht Guardrails – selbst im Prototypenstadium.
RAG auf strukturierten Daten ist kein Vektorproblem. Es ist ein Designproblem. Und erst wenn du semantische Suche, exakte Berechnung und klaren Prompt-Engineering kombinierst, bekommst du ein System, das wirklich antworten kann – nicht nur ahnt.
Schreibe einen Kommentar